Modèle linéaire : Régression en crête bayésienne
La régression bayésienne permet un mécanisme naturel pour survivre à des données insuffisantes ou mal distribuées en formulant la régression linéaire en utilisant des distributions de probabilité plutôt que des estimations ponctuelles. La sortie ou la réponse "y" est supposée être tirée d'une distribution de probabilité plutôt qu'estimée comme une valeur unique.
Mathématiquement, pour obtenir un modèle entièrement probabiliste, la réponse y est supposée être distribuée de manière gaussienne autour de Xw𝑋 comme suit :
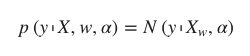
L'un des types de régression bayésienne les plus utiles est la régression bayésienne de crête qui estime un modèle probabiliste du problème de régression. Ici, l'antériorité du coefficient w est donnée par une gaussienne sphérique, comme suit -
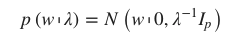
Ce modèle résultant est appelé Bayesian Ridge Regression et dans scikit-learn sklearn.linear_model.BeyesianRidge est le module utilisé.
Paramètres
La liste suivante présente les paramètres utilisés par le module BayesianRidge :
- n_iter - int, facultatif. Il représente le nombre maximum d'itérations. La valeur par défaut est 300 mais la valeur définie par l'utilisateur doit être supérieure ou égale à 1.
- fit_intercept - Booléen, facultatif, par défaut True. Il décide si l'intercept doit être calculé pour ce modèle ou non. Aucune interception ne sera utilisée dans le calcul, si elle est définie à false.
- tol - float, optionnel, default=1.e-3. Il représente la précision de la solution et arrêtera l'algorithme si w a convergé.
- alpha_1 - float, optional, default=1.e-6. C'est le 1er hyperparamètre qui est un paramètre de forme pour la distribution Gamma antérieure au paramètre alpha.
- alpha_2 - float, optional, default=1.e-6. C'est le 2ème hyperparamètre qui est un paramètre d'échelle inverse pour la distribution Gamma antérieure au paramètre alpha.
- lambda_1 - float, optional, default=1.e-6. C'est le 1er hyperparamètre qui est un paramètre de forme pour la distribution Gamma antérieure au paramètre lambda.
- lambda_2 - float, optional, default=1.e-6. Il s'agit du 2ème hyperparamètre qui est un paramètre d'échelle inverse pour la priorité de la distribution Gamma sur le paramètre lambda.
- copy_X - Booléen, facultatif, par défaut = True. Par défaut, il est vrai, ce qui signifie que X sera copié. Mais s'il est défini à false, X peut être écrasé.
- compute_score - booléen, facultatif, par défaut=False. S'il est défini à true, il calcule la vraisemblance marginale logarithmique à chaque itération de l'optimisation.
- verbose - Booléen, facultatif, par défaut=False. Par défaut, il est faux mais s'il est vrai, le mode verbeux sera activé pendant l'ajustement du modèle.
Attributs

Besoin d'aide ?
Rejoignez notre communauté officielle et ne restez plus seul à bloquer sur un problème !