Modèle linéaire : Régression en crête
20 min
Niveau 4
La régression en crête ou régularisation de Tikhonov est la technique de régularisation qui effectue une régularisation L2. Elle modifie la fonction de perte en ajoutant la pénalité (quantité de rétrécissement) équivalente au carré de la magnitude des coefficients.
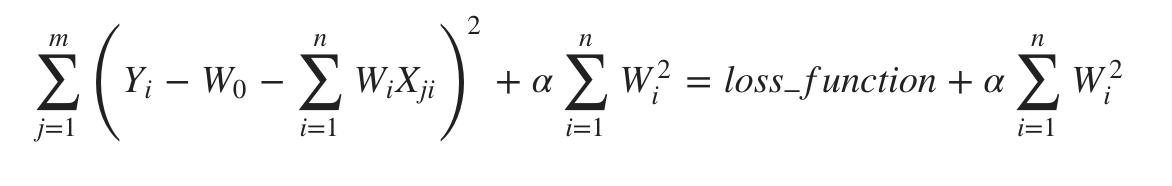
sklearn.linear_model.Ridge est le module utilisé pour résoudre un modèle de régression où la fonction de perte est la fonction linéaire des moindres carrés et la régularisation est L2.
Paramètres
La liste suivante présente les paramètres utilisés par le module Ridge :
- alpha - {float, array-like}, shape(n_targets). Alpha est le paramètre d'ajustement qui détermine dans quelle mesure nous voulons pénaliser le modèle.
- fit_intercept - Booléen. Ce paramètre spécifie si une constante (biais ou intercept) doit être ajoutée à la fonction de décision. Aucun intercept ne sera utilisé dans le calcul, s'il est défini à false.
- tol - float, facultatif, default=1e-4. Il représente la précision de la solution.
- normalize - booléen, facultatif, valeur par défaut = False. Si ce paramètre est défini sur True, le régresseur X sera normalisé avant la régression. La normalisation sera effectuée en soustrayant la moyenne et en la divisant par la norme L2. Si fit_intercept = False, ce paramètre sera ignoré.
- copy_X - Booléen, facultatif, par défaut = True. Par défaut, il est vrai, ce qui signifie que X sera copié. Mais s'il est défini à false, X peut être écrasé.
- max_iter - int, facultatif. Comme son nom l'indique, il représente le nombre maximum d'itérations prises pour les solveurs de gradient conjugué.
- solver - str, {'auto', 'svd', 'cholesky', 'lsqr', 'sparse_cg', 'sag', 'saga'}. Ce paramètre indique le solveur à utiliser dans les routines de calcul. Les propriétés des options de ce paramètre sont les suivantes :
- auto - Il permet de choisir automatiquement le solveur en fonction du type de données.
- svd - Afin de calculer les coefficients de Ridge, ce paramètre utilise une décomposition en valeurs singulières de X.
- cholesky - Ce paramètre utilise la fonction standard scipy.linalg.solve() pour obtenir une solution à forme fermée.
- lsqr - Ce paramètre est le plus rapide et utilise la routine de moindres carrés régularisés dédiée scipy.sparse.linalg.lsqr.
- sag - Elle utilise un processus itératif et une descente de gradient moyenne stochastique.
- saga - Il utilise également un processus itératif et une descente de gradient moyenne stochastique améliorée.
- random_state - int, RandomState instance ou None, facultatif, par défaut = none. Ce paramètre représente la graine du nombre pseudo-aléatoire généré qui est utilisé lors du brassage des données. Les options suivantes sont disponibles :
- int - Dans ce cas, random_state est la graine utilisée par le générateur de nombres aléatoires.
- RandomState instance - Dans ce cas, random_state est le générateur de nombres aléatoires.
- None - Dans ce cas, le générateur de nombres aléatoires est l'instance RandonState utilisée par np.random.
Attributs

Besoin d'aide ?
Rejoignez notre communauté officielle et ne restez plus seul à bloquer sur un problème !