Modèle linéaire : LASSO
20 min
Niveau 5
LASSO (Opérateur de sélection et de rétrécissement le moins absolu - Least Absolute Shrinkage and Selection Operator) est la technique de régularisation qui effectue une régularisation L1. Elle modifie la fonction de perte en ajoutant la pénalité (quantité de rétrécissement) équivalente à la somme de la valeur absolue des coefficients.
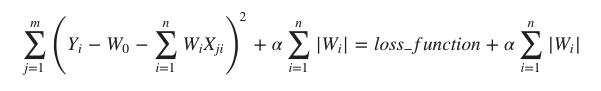
sklearn.linear_model.lasso est un modèle linéaire, avec un terme de régularisation ajouté, utilisé pour estimer des coefficients épars.
Paramètres
La liste suivante présente les paramètres utilisés par le module Lasso.
- alpha - flottant, facultatif, par défaut = 1,0. Alpha, la constante qui multiplie le terme L1, est le paramètre d'accord qui décide dans quelle mesure nous voulons pénaliser le modèle. La valeur par défaut est 1.0.
- fit_intercept - Booléen, facultatif. Par défaut=True. Ce paramètre indique qu'une constante (biais ou intercept) doit être ajoutée à la fonction de décision. Aucun intercept ne sera utilisé dans le calcul, s'il est défini à false.
- tol - flottant, facultatif. Ce paramètre représente la tolérance pour l'optimisation. La valeur tol et les mises à jour seront comparées et si les mises à jour trouvées sont inférieures à tol, l'optimisation vérifie l'optimalité du double écart et continue jusqu'à ce qu'il soit inférieur à tol.
- normalize - Booléen, facultatif, par défaut = False. Si ce paramètre est défini sur True, le régresseur X sera normalisé avant la régression. La normalisation sera effectuée en soustrayant la moyenne et en la divisant par la norme L2. Si fit_intercept = False, ce paramètre sera ignoré.
- copy_X - Booléen, facultatif, par défaut = True. Par défaut, il est vrai, ce qui signifie que X sera copié. Mais s'il est défini à false, X peut être écrasé.
- max_iter - int, facultatif. Comme son nom l'indique, il représente le nombre maximum d'itérations prises pour les solveurs à gradient conjugué.
- precompute - True|False|array-like, default=False. Avec ce paramètre, nous pouvons décider d'utiliser une matrice de Gram précalculée pour accélérer le calcul ou non.
- warm_start - bool, optionnel, par défaut = false. Avec ce paramètre réglé sur True, nous pouvons réutiliser la solution de l'appel précédent à fit comme initialisation. Si nous choisissons la valeur par défaut, c'est-à-dire false, cela effacera la solution précédente.
- random_state - int, RandomState instance ou None, facultatif, par défaut = none. Ce paramètre représente la graine du nombre pseudo-aléatoire généré qui est utilisé lors du brassage des données. Les options suivantes sont disponibles :
- int - Dans ce cas, random_state est la graine utilisée par le générateur de nombres aléatoires.
- RandomState instance - Dans ce cas, random_state est le générateur de nombres aléatoires.
- None - Dans ce cas, le générateur de nombres aléatoires est l'instance RandonState utilisée par np.random.
- selection - str, default='cyclic' (sélection)
- Cyclique - La valeur par défaut est cyclique, ce qui signifie que les caractéristiques seront bouclées séquentiellement par défaut.
- Random - Si nous définissons la sélection comme aléatoire, un coefficient aléatoire sera mis à jour à chaque itération.
Attributs

Besoin d'aide ?
Rejoignez notre communauté officielle et ne restez plus seul à bloquer sur un problème !