Évaluation de la performance de la mise en grappes
Introduction
Il existe plusieurs fonctions à l'aide desquelles nous pouvons évaluer la performance des algorithmes de clustering.
Voici quelques-unes des fonctions les plus importantes et les plus utilisées fournies par Scikit-learn pour évaluer la performance du clustering.
Indice Rand ajusté
Rand Index est une fonction qui calcule une mesure de similarité entre deux clusters. Pour ce calcul, l'indice de Rand considère toutes les paires d'échantillons et compte les paires qui sont assignées dans les clusters similaires ou différents dans le clustering prédit et le clustering réel. Ensuite, le score brut de l'indice Rand est "ajusté pour le hasard" dans le score de l'indice Rand ajusté en utilisant la formule suivante -
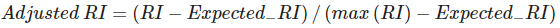
Il a deux paramètres : labels_true, qui sont les étiquettes de classe de la vérité du sol, et labels_pred, qui sont les étiquettes des clusters à évaluer.

Besoin d'aide ?
Rejoignez notre communauté officielle et ne restez plus seul à bloquer sur un problème !