Classification avec Naïve Bayes
Introduction
Les méthodes de Naïve Bayes sont un ensemble d'algorithmes d'apprentissage supervisé basés sur l'application du théorème de Bayes avec l'hypothèse forte que tous les prédicteurs sont indépendants les uns des autres, c'est-à-dire que la présence d'une caractéristique dans une classe est indépendante de la présence de toute autre caractéristique dans la même classe. Il s'agit d'une hypothèse naïve, c'est pourquoi ces méthodes sont appelées méthodes Naïve Bayes.
Le théorème de Bayes établit la relation suivante afin de trouver la probabilité postérieure de la classe, c'est-à-dire la probabilité d'une étiquette et de certaines caractéristiques observées, P( Y⏐features ) :
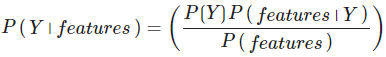
- P( Y⏐features ) est la probabilité postérieure de la classe.
- P( Y ) est la probabilité antérieure de la classe.
- P( features⏐Y ) est la vraisemblance qui est la probabilité du prédicteur étant donné la classe.
- P( features ) est la probabilité antérieure du prédicteur.
Scikit-learn fournit différents modèles de classificateurs Bayes naïfs, à savoir gaussien, multinomial, complémentaire et bernoullien. Tous ces modèles diffèrent principalement par l'hypothèse qu'ils font concernant la distribution de P( features⏐Y ) c'est-à-dire la probabilité que le prédicteur soit donné à la classe.
Modèle et description
- Gaussian Naïve Bayes - Le classifieur gaussien de Naïve Bayes suppose que les données de chaque étiquette sont tirées d'une distribution gaussienne simple.
- Multinomial Naïve Bayes - Il suppose que les caractéristiques sont tirées d'une distribution multinomiale simple.
- Bernoulli Naïve Bayes - L'hypothèse de ce modèle est que les caractéristiques sont de nature binaire (0 et 1). Une application de la classification de Bernoulli Naïve Bayes est la classification de textes avec le modèle "sac de mots".
- Complement Naïve Bayes - Il a été conçu pour corriger les hypothèses sévères faites par le classificateur Multinomial Bayes. Ce type de classificateur NB est adapté aux ensembles de données déséquilibrés.
Building Naïve Bayes Classifier
Nous pouvons également appliquer le classificateur Naïve Bayes au jeu de données Scikit-learn. Dans l'exemple ci-dessous, nous appliquons GaussianNB et ajustons le jeu de données breast_cancer de Scikit-leran.

Besoin d'aide ?
Rejoignez notre communauté officielle et ne restez plus seul à bloquer sur un problème !